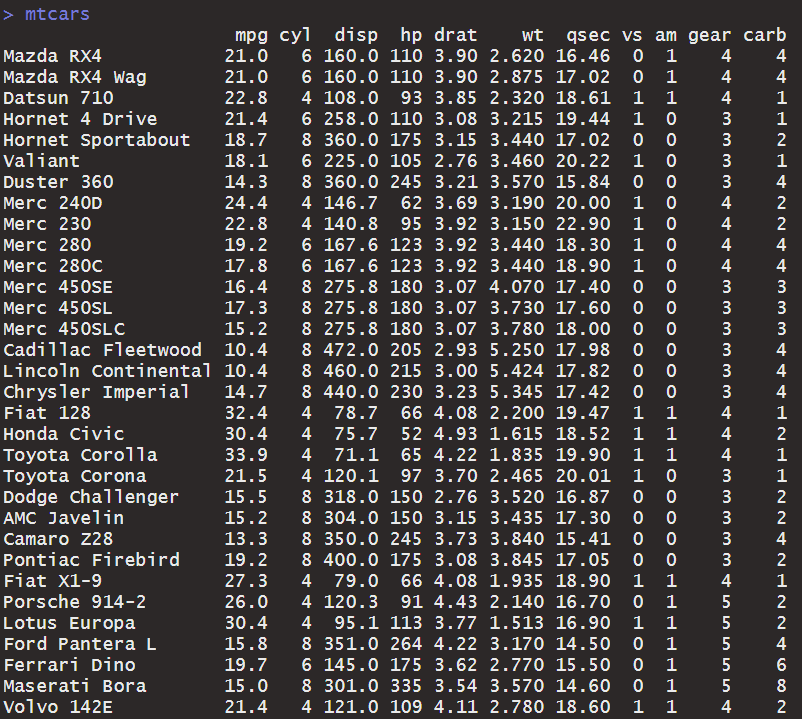
> summary(mtcars[myvars]) mpg hp wt Min. :10.40 Min. :52.0 Min. :1.513 1st Qu.:15.431st Qu.:96.51st Qu.:2.581 Median :19.20 Median :123.0 Median :3.325 Mean :20.09 Mean :146.7 Mean :3.217 3rd Qu.:22.803rd Qu.:180.03rd Qu.:3.610 Max. :33.90 Max. :335.0 Max. :5.424
> library(psych) # 相关先前引入的同名函数被覆盖 Attaching package:'psych' The following object is masked from ‘package:Hmisc’:
describe
The following objects are masked from ‘package:ggplot2’:
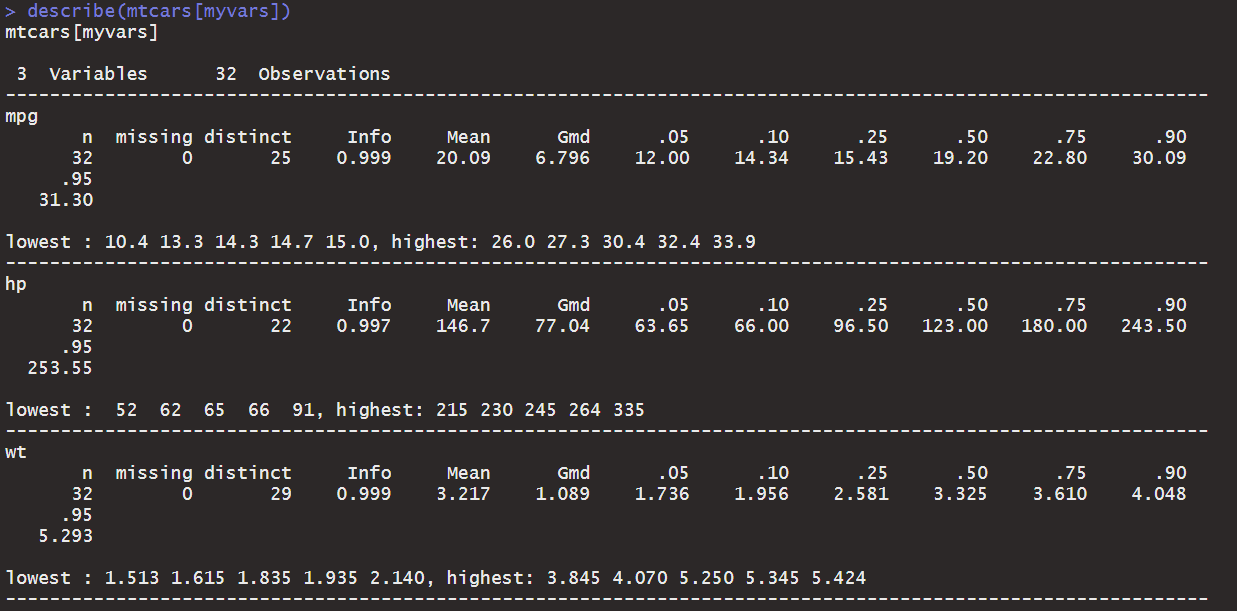
%+%, alpha > myvars <-c("mpg","hp","wt") > describe(mtcars[myvars]) vars n mean sd median trimmed mad minmaxrange skew kurtosis se mpg 13220.096.0319.2019.705.4110.4033.9023.500.61-0.371.07 hp 232146.6968.56123.00141.1977.1052.00335.00283.000.73-0.1412.12 wt 3323.220.983.333.150.771.515.423.910.42-0.020.17
> name <-c('a','h','b','c','d','e') > age <-c(18,16,12,14,16,14) > gender <-c('M','M',"F",'F',"F",'F') > height <-c(180,170,120,140,160,150) > frame1 <- data.frame(name=name,age=age,gender=gender,height=height) > frame1 name age gender height 1 a 18 M 180 2 b 16 M 170 3c12F120 4 d 14F140 5 e 16F160 6 f 14F150
> aggregate(frame1, by =list(Group.age=frame1$age), FUN = mean) Group.age name age gender height 112NA12NA120 214NA14NA145 316NA16NA165 418NA18NA180
多因子分组:在这个例子当中,按照年龄和性别分组,并求每组的最大值。
1 2 3 4 5 6 7
> aggregate(frame1, by =list(Group.age=frame1$age, Group.gender=frame1$gender), FUN =max) Group.age Group.gender name age gender height 112Fc12F120 214F f 14F150#找到了age=14,gender=F这一组中的最大值 316F e 16F160 416 M b 16 M 170 518 M a 18 M 180
> name <-c('a','h','b','c','d','e') > age <-c(18,16,12,14,16,14) > gender <-c('M','M',"F",'F',"F",'F') > height <-c(180,170,120,140,160,150) > frame1 <- data.frame(name=name,age=age,gender=gender,height=height) > frame1 name age gender height 1 a 18 M 180 2 b 16 M 170 3c12F120 4 d 14F140 5 e 16F160 6 f 14F150
分组,并且使用预设的summar函数进行初步分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
> by(frame1, frame1$gender, summary) frame1$gender:F name age gender height Length:4 Min. :12.0 Length:4 Min. :120.0 Class :character 1st Qu.:13.5 Class :character 1st Qu.:135.0 Mode :character Median :14.0 Mode :character Median :145.0 Mean :14.0 Mean :142.5 3rd Qu.:14.53rd Qu.:152.5 Max. :16.0 Max. :160.0 --------------------------------------------------------------------------------- frame1$gender: M name age gender height Length:2 Min. :16.0 Length:2 Min. :170.0 Class :character 1st Qu.:16.5 Class :character 1st Qu.:172.5 Mode :character Median :17.0 Mode :character Median :175.0 Mean :17.0 Mean :175.0 3rd Qu.:17.53rd Qu.:177.5 Max. :18.0 Max. :180.0
分隔符号,左边为响应变量,右边为解释变量。例如,要通过 x、z 和 w 预测 y,代码为 y ~ x + z + w
+
分隔预测变量
:
表示预测变量的交互项。例如,要通过 x、z 及 x 与 z 的交互项预测 y,代码为 y ~ x + z + x:z
*
表示所有可能交互项的简洁方式。代码 y~ x * z * w 可展开为 y ~ x + z + w + x:z + x:w + z:w + x:z:w
^
表示交互项达到某个次数。代码 y ~ (x + z + w)^2 可展开为 y ~ x + z + w + x:z + x:w + z:w
.
表示包含除因变量外的所有变量。例如,若一个数据框包含变量 x、y、z 和 w,代码 y ~ . 可展开为 y ~ x + z + w
-
减号,表示从等式中移除某个变量。例如,y ~ (x + z + w)^2 – x:w 可展开为 y ~ x + z + w + x:z + z:w
-1
删除截距项。例如,表达式 y ~ x - 1 拟合 y 在 x 上的回归,并强制直线通过原点
I()
从算术的角度来解释括号中的元素。例如,y ~ x + (z + w)^2 将展开为 y ~ x + z + w + z:w。 相反, 代码 y ~ x + I((z + w)^2)将展开为 y ~ x + h,h 是一个由 z 和 w 的平方和创建的新变量
function
可以在表达式中用的数学函数。例如,log(y) ~ x + z + w 表示通过 x、z 和 w 来预测 log(y)
例:
2. 频数表和列联表
本节中的数据来自vcd包中的Arthritis数据集。这份数据来自Kock & Edward (1988),表示了一项风湿性关节炎新疗法的双盲临床实验的结果。前几个观测是这样的:
1 2 3 4 5 6 7 8 9 10
> library(vcd) 载入需要的程辑包:grid > head(Arthritis) ID Treatment Sex Age Improved 157 Treated Male 27 Some 246 Treated Male 29 None 377 Treated Male 30 None 417 Treated Male 32 Marked 536 Treated Male 46 Marked 623 Treated Male 58 Marked
依 margins 定义的边际列表将表中条目表示为分数形式 margin is a vector giving the margins to compute sums for a matrix 1 indicates rows, 2 indicates columns, c(1, 2) indicates rows and columns. 下同
margin.table(table, margins)
依 margins 定义的边际列表计算表中条目的和
addmargins(table, margins)
将概述边 margins(默认是求和结果)放入表中
ftable(table)
创建一个紧凑的“平铺”式列联表
(1) 一维列联表
可以使用table()函数生成简单的频数统计表。示例如下:
1 2 3 4 5
> data1 <- table(Arthritis$Improved) > data1
None Some Marked 421428
可以用prop.table()将这些频数转化为比例值:
1 2 3 4
> prop.table(data1)
None Some Marked 0.50000000.16666670.3333333
或使用prop.table()*100转化为百分比:
1 2 3 4
> prop.table(data1)*100
None Some Marked 50.0000016.6666733.33333
(2) 二维列联表
函数table()
对于二维列联表,table()函数的使用格式为:
mytable <- table(A, B)
其中的A是行变量,B是列变量。
例:
构建数据集:
1 2 3 4 5 6 7 8 9 10 11 12 13
> name <-c('a','h','b','c','d','e') > age <-c(18,16,12,14,16,14) > gender <-c('M','M',"F",'F',"F",'F') > height <-c(180,170,120,140,160,150) > frame1 <- data.frame(name=name,age=age,gender=gender,height=height) > frame1 name age gender height 1 a 18 M 180 2 b 16 M 170 3c12F120 4 d 14F140 5 e 16F160 6 f 14F150
制表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
> table(frame1$name,frame1$age)
12141618 a 0001 b 1000 c0100 d 0010 e 0100 h 0010 > table(frame1$name,frame1$gender)
> library(vcd) 载入需要的程辑包:grid > head(Arthritis) ID Treatment Sex Age Improved 157 Treated Male 27 Some 246 Treated Male 29 None 377 Treated Male 30 None 417 Treated Male 32 Marked 536 Treated Male 46 Marked 623 Treated Male 58 Marked
Cell Contents |-------------------------| | N | | Chi-square contribution | | N / Row Total | | N / Col Total | | N / Table Total | |-------------------------|
# 对第二维度(本例中为Sex)求和 > margin.table(table1,2) Sex Female Male 5925
# 对第三维度(本例中为Improved)求和 > margin.table(table1,3) Improved None Some Marked 421428
# 对1,2维度求和,即重新构建次级表格 > margin.table(table1,c(1,2)) Sex Treatment Female Male Placebo 3211 Treated 2714
# 对2,3维度求和,不同的顺序可以改变输出表格的行列 > margin.table(table1,c(2,3)) Improved Sex None Some Marked Female 251222 Male 1726
> margin.table(table1,c(3,2)) Sex Improved Female Male None 2517 Some 122 Marked 226
prob.table(): 为了方便展示,这里使用了ftable()
margin使用的方法同margin.table
1 2 3 4 5 6 7 8
# 按照第一维度进行求概率 > ftable(prop.table(table1,1)) Improved None Some Marked Treatment Sex Placebo Female 0.441860470.162790700.13953488 Male 0.232558140.000000000.02325581 Treated Female 0.146341460.121951220.39024390 Male 0.170731710.048780490.12195122
addmargins():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# 计算原表1,2维度上各项的概率,同时计算各个项在第3维度的概率和 > ftable(addmargins(prop.table(table1,c(1,2)),3)) Improved None Some Marked Sum Treatment Sex Placebo Female 0.593750000.218750000.187500001.00000000 Male 0.909090910.000000000.090909091.00000000 Treated Female 0.222222220.185185190.592592591.00000000 Male 0.500000000.142857140.357142861.00000000
# 计算原表1,2维度上各项的概率,同时计算各个项在第2维度的概率和 > ftable(addmargins(prop.table(table1,c(1,2)),2)) Improved None Some Marked Treatment Sex Placebo Female 0.593750000.218750000.18750000 Male 0.909090910.000000000.09090909 Sum 1.502840910.218750000.27840909 Treated Female 0.222222220.185185190.59259259 Male 0.500000000.142857140.35714286 Sum 0.722222220.328042330.94973545
二、单项描述性统计分析
数学函数
函数
描述
abs(x)
绝对值
sqrt()
平方根
ceiling(x)
不小于 x 的最小整数, ceiling(3.475)返回值为 4
floor(x)
不大于 x 的最大整数, floor(3.475)返回值为 3
trunc(x)
向 0 的方向截取的 x 中的整数部分, trunc(5.99)返回值为 5
round(x, digits=n)
将 x 舍入为指定位的小数, round(3.475, digits=2)返回值为 3.48
signif(x, digits=n)
将 x 舍入为指定的有效数字位数, signif(3.475, digits=2)返回值为 3.5
cos(x)、sin(x)、tan(x)
余弦、正弦和正切
acos(x)、asin(x)、atan(x)
反余弦、反正弦和反正切
cosh(x)、sinh(x)、tanh(x)
双曲余弦、双曲正弦和双曲正切
acosh(x)、asinh(x)、atanh(x)
反双曲余弦、反双曲正弦和反双曲正切
log(x,base=n) log(x) log10(x)
对 x 取以 n 为底的对数 为了方便起见: log(x)为自然对数 log10(x)为常用对数 log(10)返回值为 2.3026 log10(10)返回值为 1
exp(x)
指数函数
统计函数
函数
描述
mean(x)
平均数,x为数值向量
median(x)
中位数
sd(x)
样本标准差: $\sum / (n-1)$ 这里的Standard Deviation是对样本的标准差,即Sample Standard Deviation,下面说的Variance也是一样