08. R <- 输入、读取、标注数据与创建报告
一、输入与读取数据
R可从键盘、文本文件、Microsoft Excel和Access、流行的统计软件、特殊格式的文件、多种关系型数据库管理系统、专业数据库、网站和在线服务中导入数据。
从键盘输入
从键盘输入数据有两种方式:
- 使用R内置的文本编辑器
- 从代码中输入
这部分的演示使用R Studio,它可以极大地方便使用R的过程。
1. 文本编辑器
R中的函数edit()会自动调用一个允许手动输入数据的文本编辑器。具体步骤如下:
- 创建一个空数据框(或矩阵),其中变量名和变量的模式需与理想中的最终数据集一致;
- 针对这个数据对象调用文本编辑器,输入你的数据,并将结果保存回此数据对象中。
在创建一个数据集的开始,可以首先规定一些变量名以及变量类型:
1 | |
如在这个例子当中,创建一个名为mydata的数据框,它含有三个变量:age(数值型)、gender(字符型)和weight(数值型)。然后你将调用文本编辑器,键入数据,最后保存结果。
age=numeric(0)的赋值语句将创建一个指定模式但不含实际数据的变量- 语句
mydata <- edit(mydata)的一种简捷的等价写法是fix(mydata)
编辑器关闭后,结果会保存到之前赋值的对象中
- 函数
edit()事实上是在对象的一个副本上进行操作的。如果你不将其赋值到一个目标,你的所有修改将会全部丢失
2. 从代码输入
与首先规定变量名相对的,也可以直接通过代码来输入:
1 | |
从带分隔符的文本文件导入数据
可以使用read.table()从带分隔符的文本文件中导入数据。此函数可读入一个表格格式的文件并将其保存为一个数据框。表格的每一行分别出现在文件中每一行。其语法如下:
1 | |
其中,file是一个带分隔符的ASCII文本文件,options是控制如何处理数据的选项:
| 选项 | 说明 |
|---|---|
| file | 文件名(包在””内,或使用一个字符型变量),可能需要全路径 在R中,路径的分割符号使用 / 而不是 \ |
| header | 一个逻辑值(FALSE或TRUE),用来反映这个文件的第一行是否包含变量名 |
| sep | 文件中的字段分离符 |
| quote | 指定用于包围字符型数据的字符 |
| dec | 用来表示小数点的字符 |
| row.names | 保存着行名的向量,或文件中一个变量的序号或名字,缺省时行号取为1,2,3,…… |
| col.names | 指定列名的字符向量 |
| as.is | 控制是否将字符型变量转化为引子型变量(如果值为FALSE),或者仍将其保留为字符型(TRUE)。As.is可以说逻辑型,数值型或者字符向量,用来判断变量是否被保留为字符 |
| na.strings | 代表确实数据的值(转化为NA) |
| colClasses | 指定各列的数据类型的一个字符型向量 |
| nrows | 可以读取的最大行数(忽略负值) |
| skip | 在读取数据前跳过的行数 |
| check.names | 如果为TRUE,则检查变量名是否在R中有效 |
| fill | 如果为TRUE且非所有的行中变量数目相同,则用空白填补 |
| strip.white | 在sep已指定的情况下,如果为TRUE,则删除字符型变量前后多余的空格 |
| blank.lines.skip | 如果为TRUE,忽略空白行 |
| comment.char | 一个字符用来在数据文件中写注释,以这个字符开头的行被忽略 |
考虑一个名为studentgrades.csv的文本文件,它包含了学生在数学、科学、和社会学习的分数。文件中每一行表示一个学生,第一行包含了变量名,用逗号分隔。每一个单独的行都包含了学生的信息,它们也是用逗号进行分隔的。文件的前几行如下:
1 | |
这个文件可以用以下语句来读入成一个数据框:
1 | |
结果如下:
1 | |
默认地,read.table()把字符变量转化为因子,这并不一定都是我们想要的情况。
加上选项stringsAsFactors=FALSE可以对所有的字符变量都去掉这个行为。
可以用colClasses选项去对每一列都指定一个类(比如说,逻辑型、数值型、字符型或因子型):
1 | |
1 | |
导入 Excel 数据
读取一个Excel文件的最好方式,就是在Excel中将其导出为一个逗号分隔文件(csv),并使用前文描述的方式将其导入R中。此外,也可以用xlsx包直接地导入Excel工作表。
xlsx包可以用来对Excel 97/2000/XP/2003/2007文件进行读取、写入和格式转换。
函数read.xlsx()导入一个工作表到一个数据框中。最简单的格式是read.xlsx(file, n),其中file是Excel工作簿的所在路径,n则为要导入的工作表序号。
- 在R中,路径的分割符号使用
/而不是\
例:
1 | |
此外,函数read.xlsx2也可以用来读取xlsx文件。它使用到了Java,有时候可以获得更加优秀的读取结果。
关于这两个函数的完成用法如下:
1 | |
相关参数:
| 参数 | 描述 |
|---|---|
| file | the path to the file to read. |
| sheetIndex | a number representing the sheet index in the workbook. |
| sheetName | a character string with the sheet name. |
| rowIndex | a numeric vector indicating the rows you want to extract. If NULL, all rows found will be extracted, unless startRow or endRow are specified. |
| startRow | a number specifying the index of starting row. For read.xlsx this argument is active only if rowIndex is NULL. |
| endRow | a number specifying the index of the last row to pull. If NULL, read all the rows in the sheet. For read.xlsx this argument is active only if rowIndex is NULL. |
| colIndex | a numeric vector indicating the cols you want to extract. If NULL, all columns found will be extracted. |
| as.data.frame | a logical value indicating if the result should be coerced into a data.frame. If FALSE, the result is a list with one element for each column. |
| header | a logical value indicating whether the first row corresponding to the first element of the rowIndex vector contains the names of the variables. |
| colClasses | For read.xlsx a character vector that represent the class of each column. Recycled as necessary, or if the character vector is named, unspecified values are taken to be NA. For read.xlsx2 see readColumns. |
| keepFormulas | a logical value indicating if Excel formulas should be shown as text in and not evaluated before bringing them in. |
| encoding | encoding to be assumed for input strings. See read.table. |
| password | a String with the password. |
以下参数继承自data.frame:
| 参数 | 描述 |
|---|---|
| row.names | NULL or a single integer or character string specifying a column to be used as row names, or a character or integer vector giving the row names for the data frame. |
| check.rows | if TRUE then the rows are checked for consistency of length and names. |
| check.names | logical. If TRUE then the names of the variables in the data frame are checked to ensure that they are syntactically valid variable names and are not duplicated. If necessary they are adjusted (by make.names) so that they are. |
| fix.empty.names | logical indicating if arguments which are “unnamed” (in the sense of not being formally called as someName = arg) get an automatically constructed name or rather name “”. Needs to be set to FALSE even when check.names is false if “” names should be kept. |
| stringsAsFactors | logical: should character vectors be converted to factors? The ‘factory-fresh’ default has been TRUE previously but has been changed to FALSE for R 4.0.0. Only as short time workaround, you can revert by setting options(stringsAsFactors = TRUE) which now warns about its deprecation. |
二、数据集的标注
为了使结果更易解读,数据分析人员通常会对数据集进行标注。这种标注包括为变量名添加描述性的标签,以及为类别型变量中的编码添加值标签。例如,对于变量age,你可能想附加一个描述更详细的标签“Age at hospitalization (in years)”(入院年龄)。对于编码为1或2的性别变量gender,你可能想将其关联到标签“male”和“female”上。
变量标签(名称)的修改
可以将变量标签作为变量名,然后通过位置下标来访问这个变量。
1. 获得标签(名称)
对象名称
函数names()可以获得或设定某个对象的名称:
1 | |
例,修改某一行或一列的名称(标签):
1 | |
行、列名称
使用函数row.names()与colnames()可以获得某个数据框的行、列名称:
1 | |
之后可以使用序号的索引对标签进行修改:
1 | |
2. 值标签的获得与修改
函数factor()可为类别型变量创建值标签。继续上例,假设你有一个名为gender的变量,其中1表示男性,2表示女性。你可以使用以下代码来创建值标签:
1 | |
这里levels代表变量的实际值,而labels表示包含了理想值标签的字符型向量。
处理数据对象的常用函数
| 函数 | 用途 |
|---|---|
| length(object) | 显示对象/元素数量、向量等数据类型长度 |
| dim(object) | 显示某个对象的维度,其中也包含数据类型的长度 |
| str(object) | 显示某个对象的结构 |
| class(object) | 显示某个对象的类或类型,整体的类型 |
| mode(object) | 显示某个对象的模式,个体类型,如每一列 |
| names(object) | 显示某对象中各成分的名称 |
| c(ob1,ob2) | 将对象合并入一个向量 |
| cbind(ob1,ob2) | 按列合并对象 |
| rbind(ob1,ob2) | 按行合并对象 |
| object | 输出某个对象 |
| head(object) | 列出某个对象的开始部分,默认前六行 |
| tail(object) | 列出某个对象的最后部分,默认后六行 |
| ls() | 显示当前的对象列表 |
| rm() | 删除一个或多个对象 |
| edit(object) | 编辑对象 |
| fix(object) | 直接编辑对象 |
三、创建报告
这部分需要使用到R Studio。
使用模板生成报告:
从模板生成报告即报告从一个模版文件开始创建。这份模版包括了报告文字、格式化语法和R代码块。
基本的流程为:读取模版文件,运行R代码,应用格式化指令,生成一个报告。
模版文件(xxx.Rmd)是一个纯文本文档这种文本文件使用扩展名.Rmd,包含以下三个部分。
- 报告文字:所有解释性的语句和文字。
- 格式化语法(formatting syntax):控制报告格式化方式的标签。(具体语法下面有简要的补充。)
- R代码:要运行的R语句。在R Markdown文档中,R代码块被
```{r} 以及
最后,模版文件被作为参数传递到 rmarkdown 包的 render() 函数中,然后创建出一个网页文件example.html,此网页包含了报告文字和R结果。
本章主要学习四种模版:R Markdown模版、ODT模版、DOCX模版和LaTeX模版。
- R Markdown模版能够用来生成HTML、PDF和Microsoft Word文档。
- ODT和DOCX模版分别用于生成Open Document和Microsoft Word文档。
- LaTeX模版则能生成出版水平的PDF文档,包括报告、 文章和图书。
用 R 和 Markdown 创建动态报告
这部分需要进行一些准备工作:
- 安装
rmarkdown包(install.packages(“rmarkdown”)) - 安装
xtable包(install.packages(“xtable”)) - 安装
Pandoc - 安装LaTeX编译器(如果想生成PDF文档)。一套LaTeX编译器能够把一个LaTeX文件转换成一个高质量排版的PDF文档。
- 注意,安装了最新版
Rstudio则可跳过第1和4步。
- 注意,安装了最新版
1. 创建报告文件
在R studio中,从GUI菜单中选择“File”→“New File”→“R Markdown”,可以可视化地创建Markdown文件。之后就会出现GUI界面,进行选择与设置。
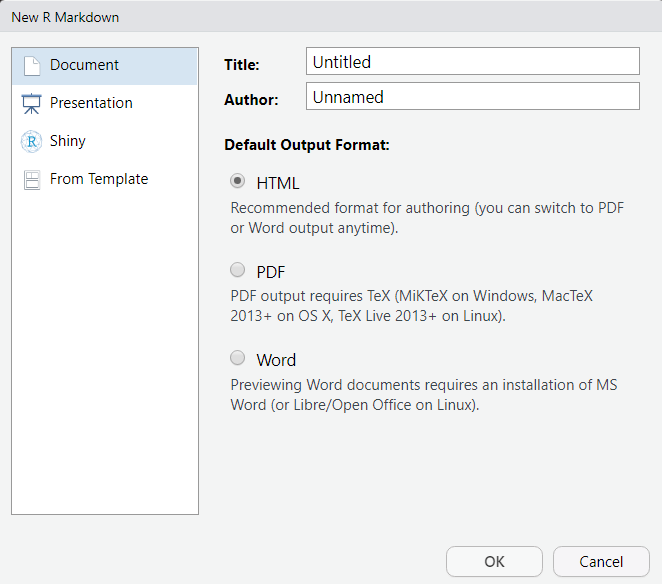
在完成设置之后,就进入到了编辑界面:
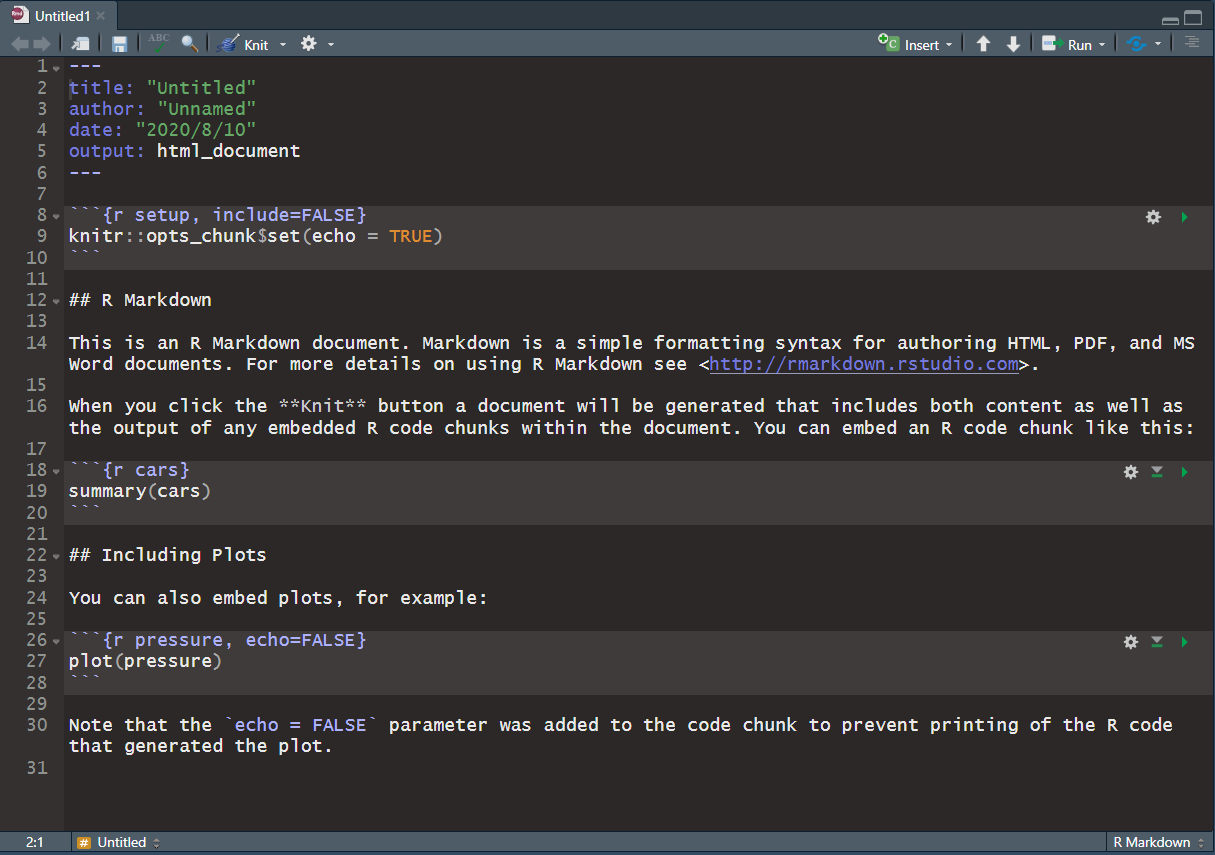
在这里,就可以进行相关代码的编辑了。
2. 报告文件语法
这部分的语法也就是Markdown的语法,就不多赘述了。
有一些值得注意的代码块选项是:
| 选项(参数) | 描述 |
|---|---|
| echo | 是否在输出中包含R源代码(TRUE或FALSE) |
| results | 是否输出原生结果(asis或hide) |
| warning | 是否在输出中包含警告(TRUE或FALSE) |
| message | 是否在输出中包含参考的信息(TRUE或FALSE) |
| error | 是否在输出中包含错误信息(TRUE或FALSE) |
| fig.width | 图片宽度(英寸) |
| fig.height | 图片高度(英寸) |
例如:
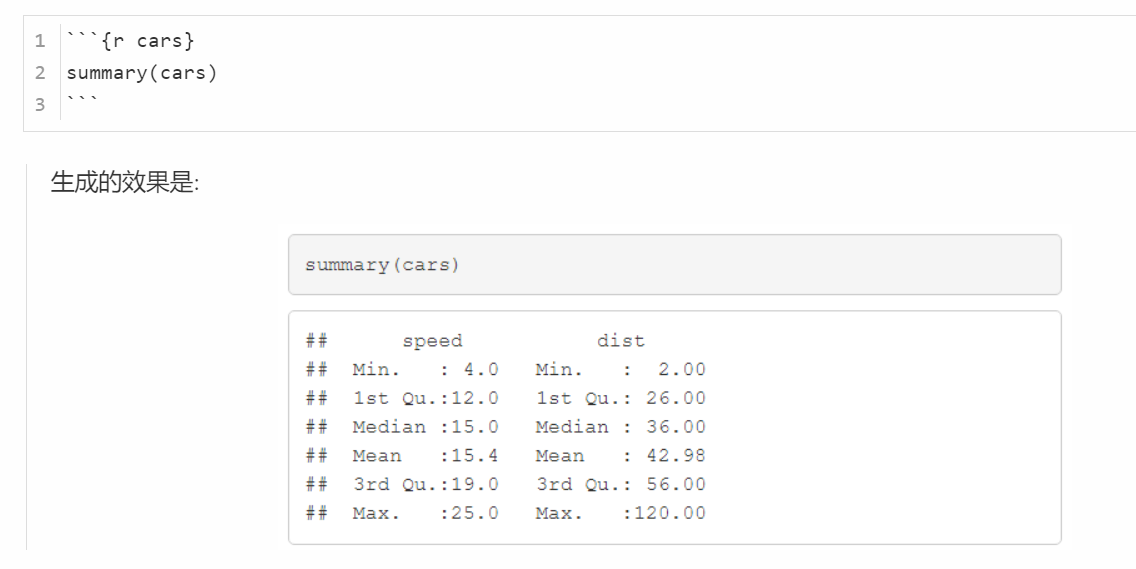
例2:

3. 文件输出
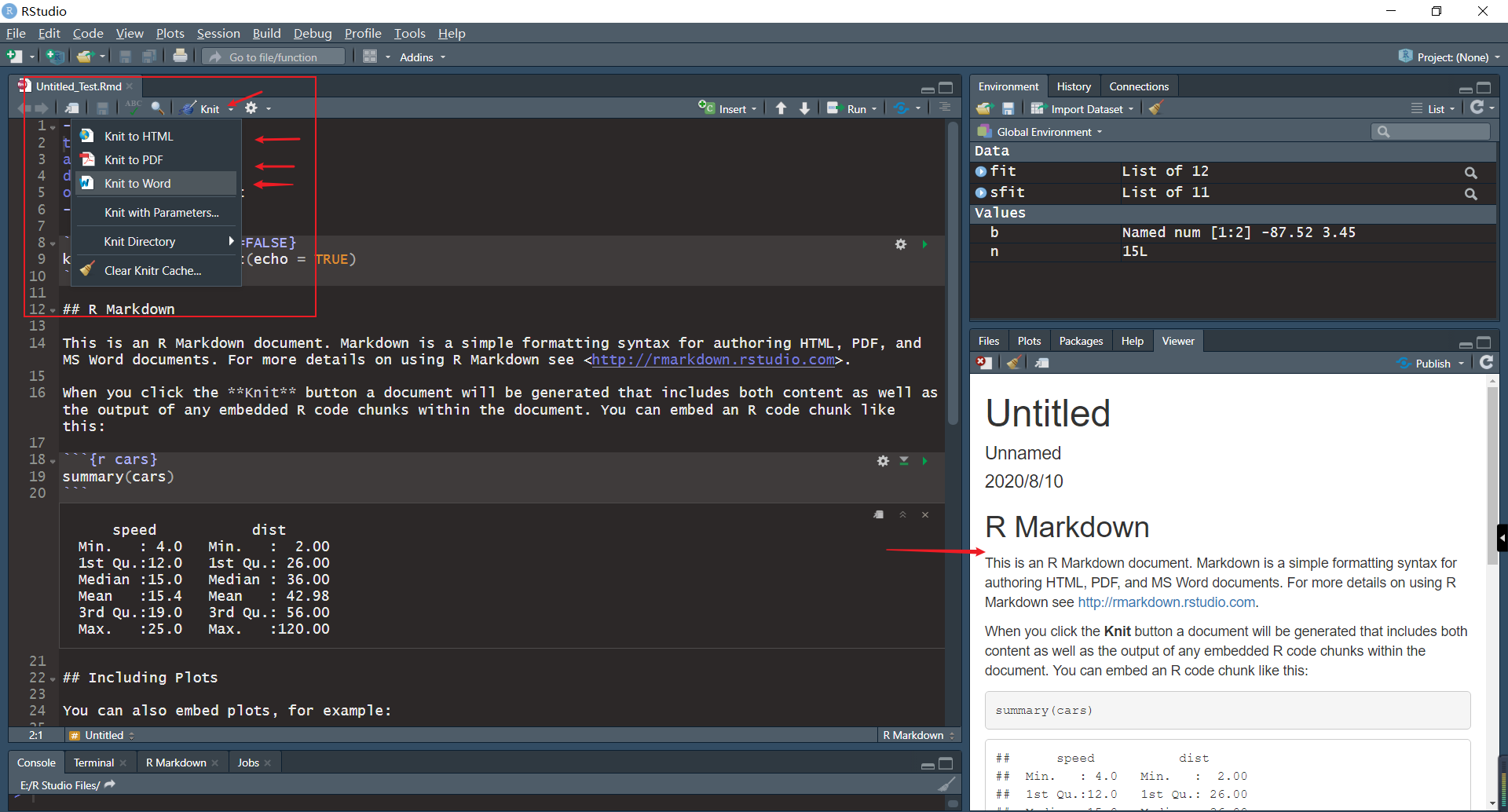
使用R Studio可以很方便地实现文件的编辑和输出。
在GUI中创建完成报告文件之后,就可以在R Studio中的一个Pane中进行代码的编辑。
而输出的话则需要从Knit下拉菜单当中选取目标输出格式,之后在Viewer Pane中预览,可以在下拉菜单中选择保存的目标路径等。